Rohan Surana
Masters Student in Data Science @ UCSD
I am a Master's student in Data Science at the University of California, San Diego (UCSD), advised by Prof. Julian McAuley, also actively collaborating with Adobe and Netflix. I previously earned my B.S. in Software Engineering, summa cum laude, from San Jose State University.
My research spans preference optimization, information retrieval, and multimodal learning. I develop methods that help LLMs learn from sparse, structured feedback: pairwise preferences, ranked lists, and in-context signals. Recent work includes multi-negative DPO with principled selection strategies, in-context ranking objectives for retrieval and recommendation, and multimodal extensions that reduce hallucinations. I also build practical systems like active dialogue synthesis for low-resource domains and benchmarks for audio-centric recommendation.
What's New
- [Dec 2025] Attending NeurIPS 2025 in San Diego, CA.
- [Sep 2025] Completed internship at Dell Technologies!
- [Jun 2025] Joined Dell Technologies as an AI Research Intern in Hopkinton, MA.
- [May 2025] Our paper "In-context Ranking Preference Optimization" was accepted to COLM 2025.
- [May 2025] Our paper "Traceable and Explainable Multimodal LLMs" was accepted to COLM 2025.
- [May 2025] Our paper "Image Difference Captioning via Adversarial Preference Optimization" was accepted to EMNLP 2025.
Research Topics
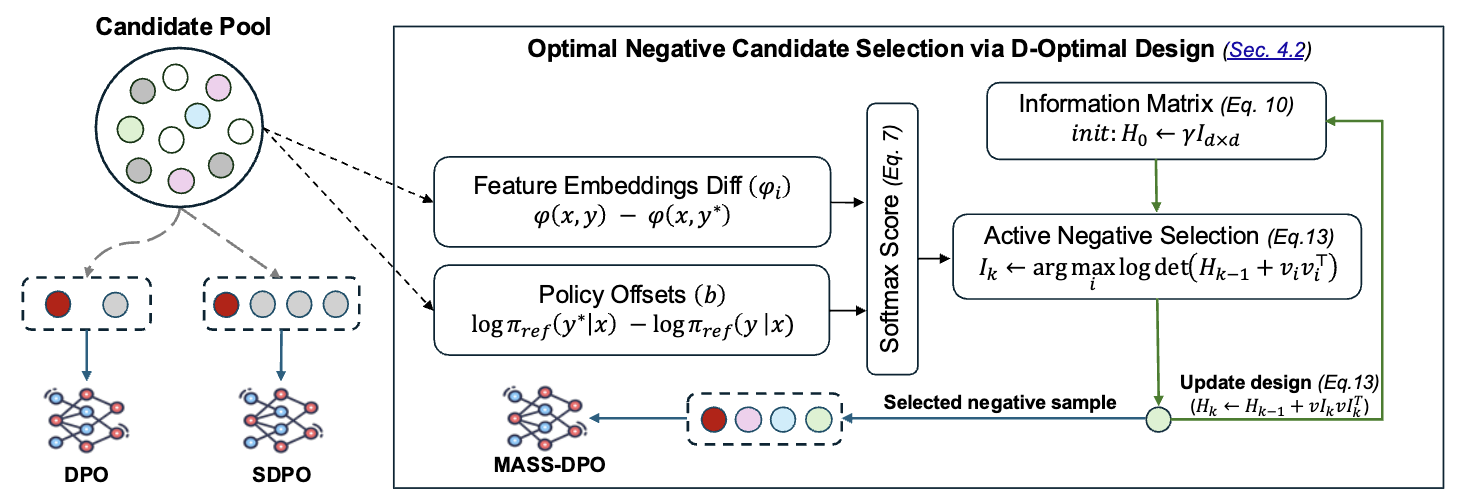
We cast multi-negative DPO under the Plackett-Luce model as a D-optimal design problem and develop a greedy, theoretically grounded selection strategy for informative negatives. This improves alignment efficiency and performance.

We extend Direct Preference Optimization to ranking, allowing LLMs to learn from sparse, in-context listwise feedback and directly optimize differentiable surrogates of ranking metrics. This connects preference optimization with practical IR settings like conversational recommendation and generative retrieval.
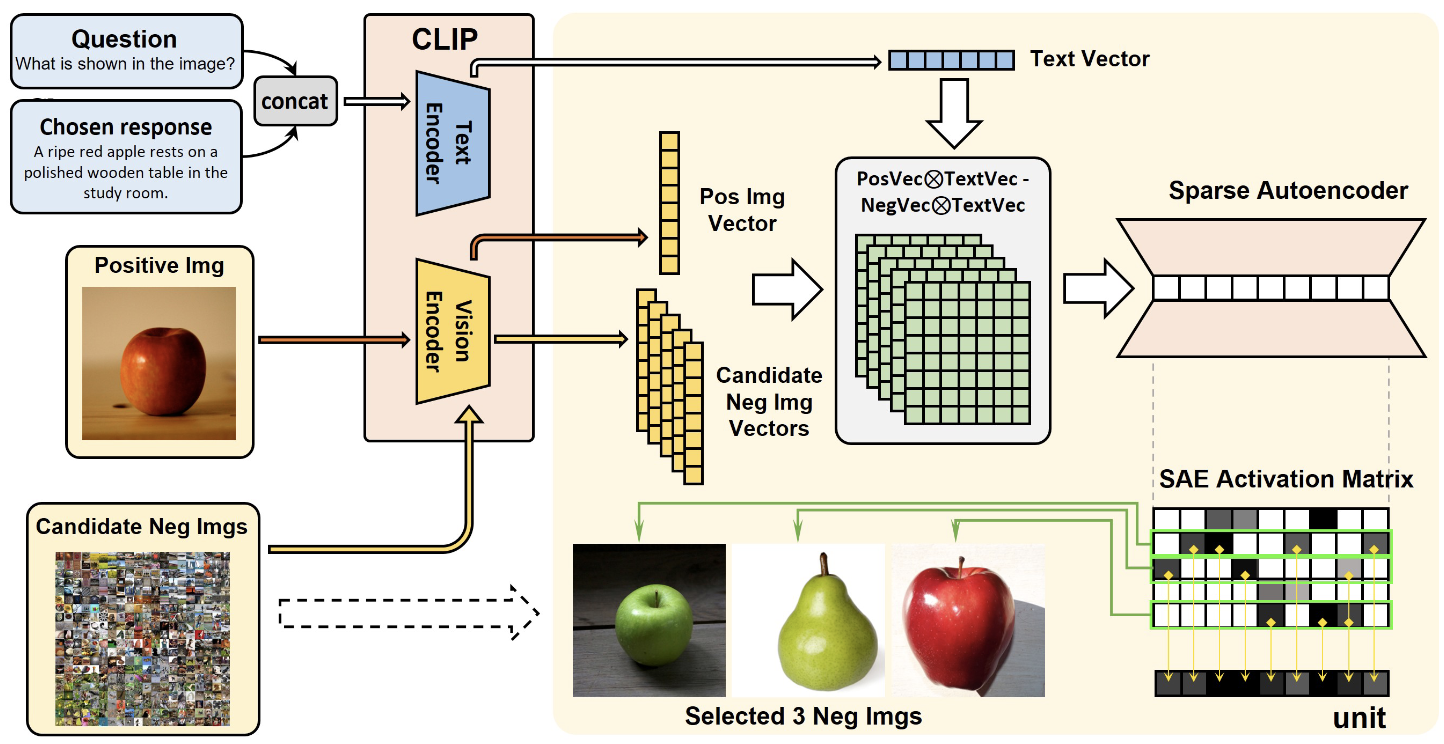
We extend multi-negative DPO to the multimodal setting, using a CLIP+SAE-based sampler and importance sampling under a Plackett–Luce objective to select semantically diverse visual negatives. This substantially improves multimodal alignment and reduces hallucinations compared to single-negative multimodal DPO baselines.
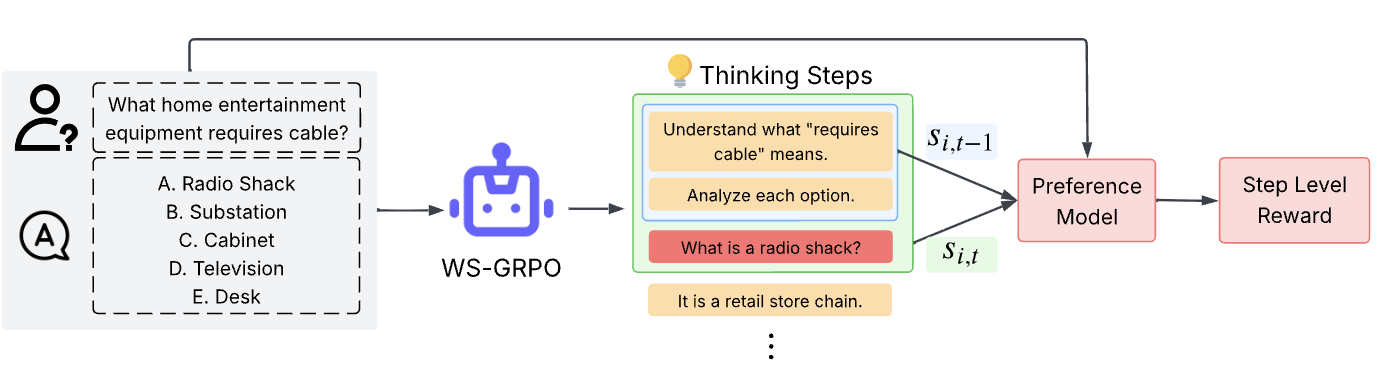
We address GRPO's dependence on dense step-wise rewards by learning to extract dense preference signals from sparse outcome supervision. WS-GRPO trains a preference model on trajectory-level outcomes, then leverages it to provide step-wise weakly-supervised rewards combined with terminal rewards during group-relative policy optimization. This enables effective reasoning model training without expensive step-by-step annotations.
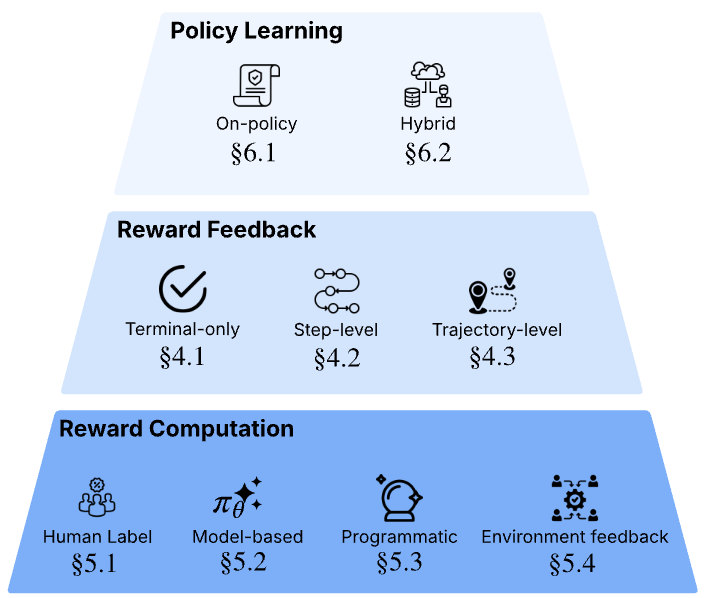
We provide the first comprehensive survey of Reinforcement Learning from Verifiable Rewards (RLVR), systematizing methods that train language models using verifier feedback. We introduce taxonomies organizing approaches by verification type, reward computation, and policy learning, establishing unified terminology for mathematical reasoning, code generation, and instruction following.
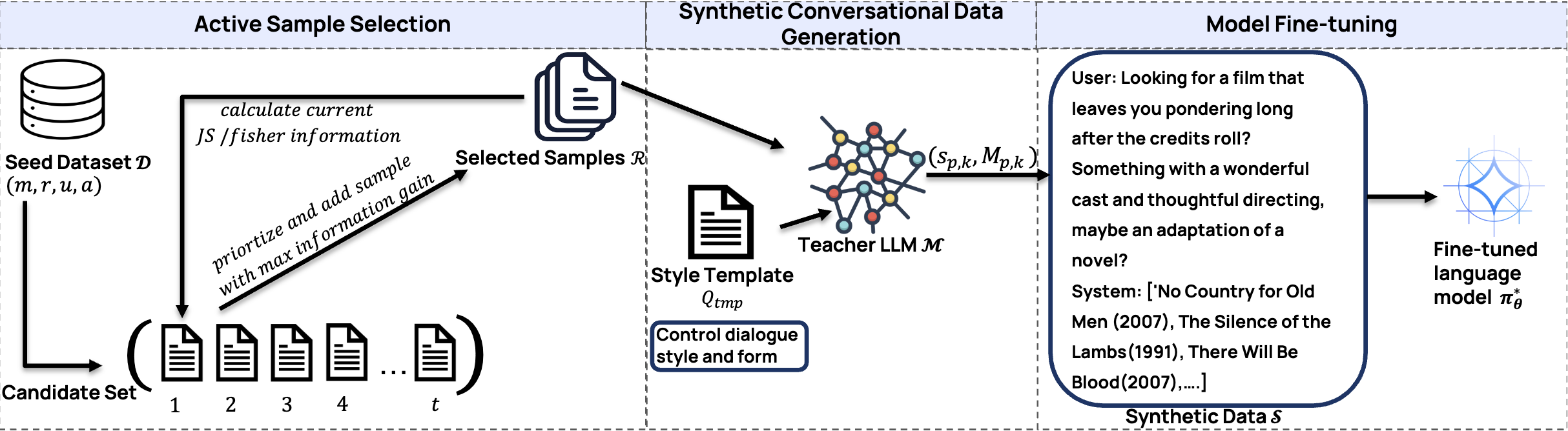
Joint work with Netflix where we design an active data augmentation framework that turns static domain data (reviews, metadata, collaborative signals) into synthetic conversations using black-box LLMs, enabling smaller in-house CRS models to operate in true zero-/low-resource settings.
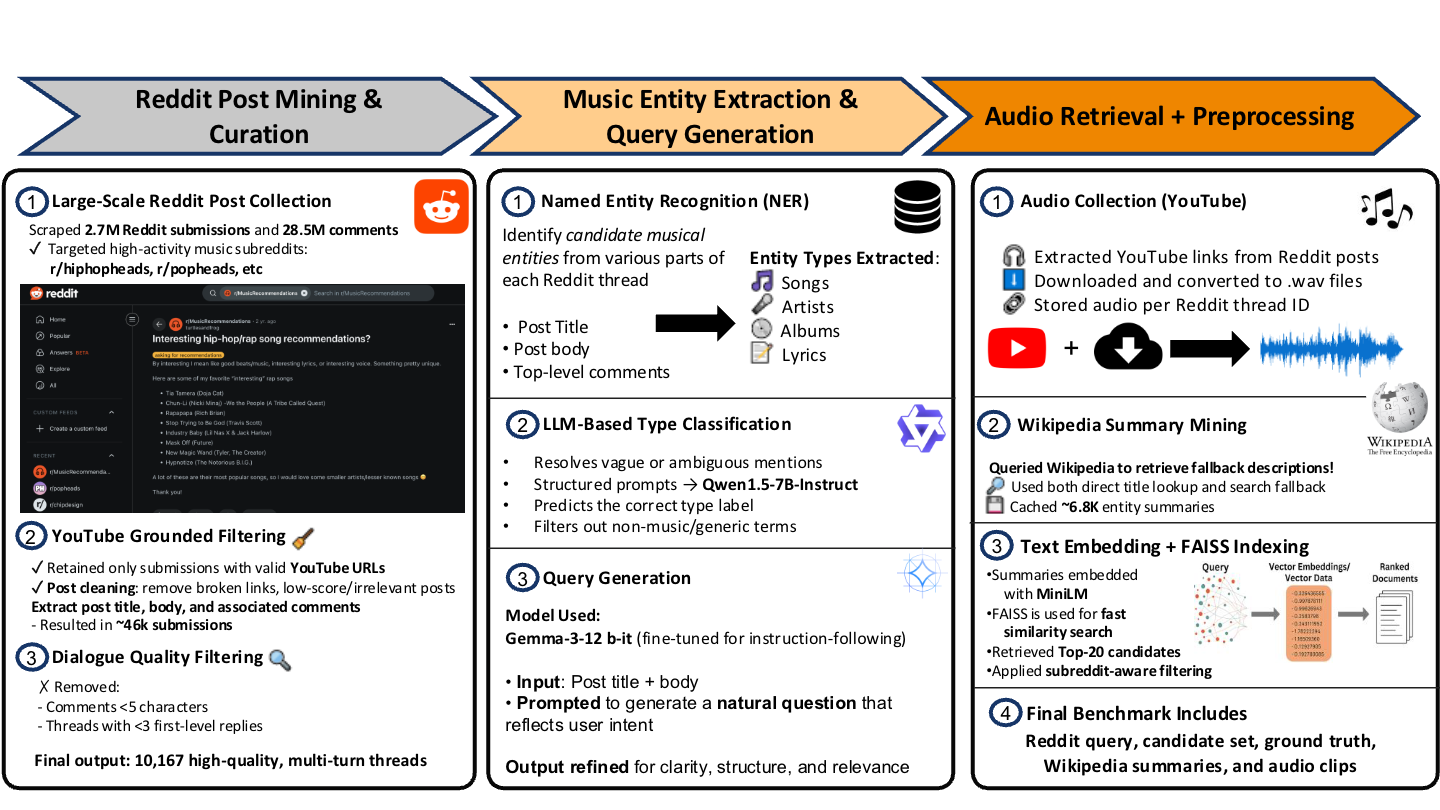
We build the first benchmark that ties real conversational queries to actual music tracks, enabling evaluation across audio-only, text-only, and audio+text settings. This exposes how current CRS models over-rely on text and struggle with nuanced audio reasoning.
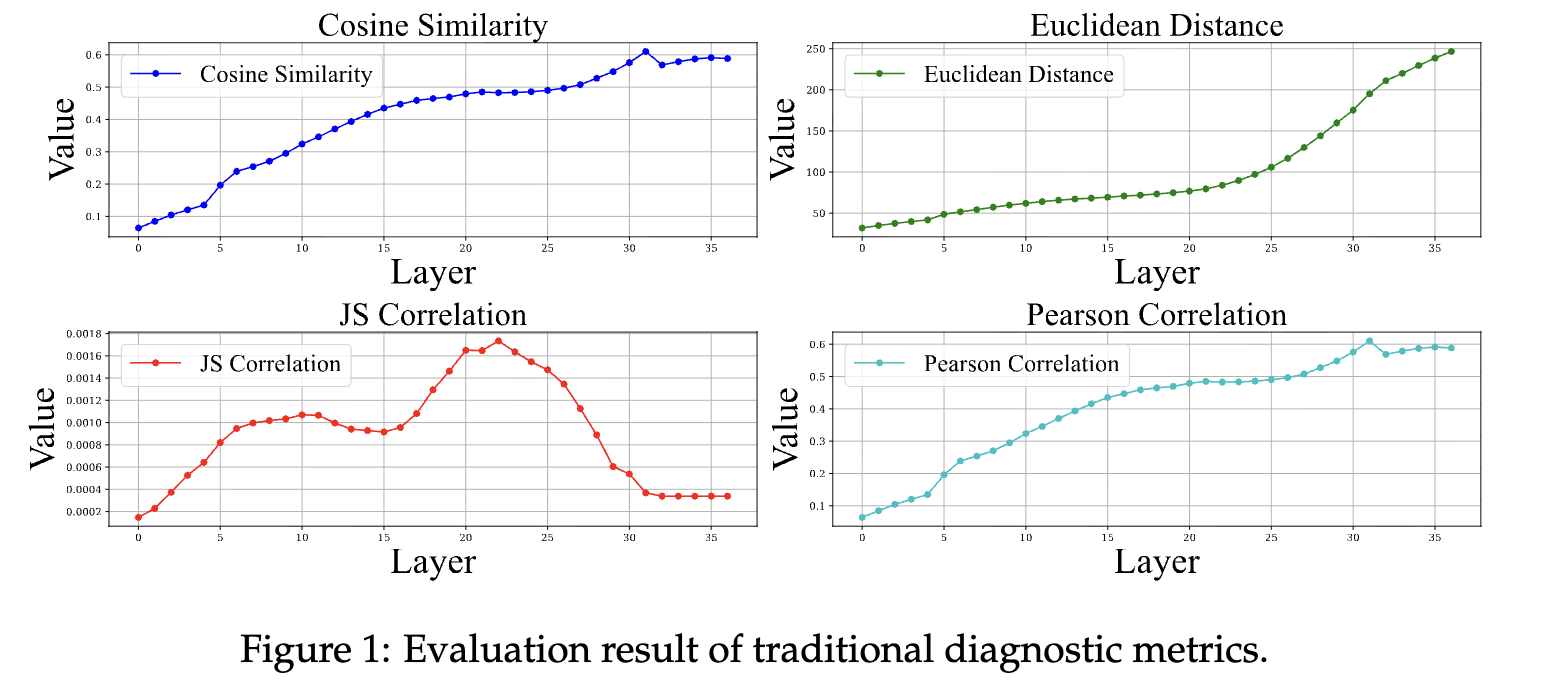
We propose an information-theoretic framework (via a concept bottleneck and mutual-information-style measures) to make MLLMs more traceable: quantifying how much visual information is retained, transformed, or discarded as it flows through the model under different textual instructions.
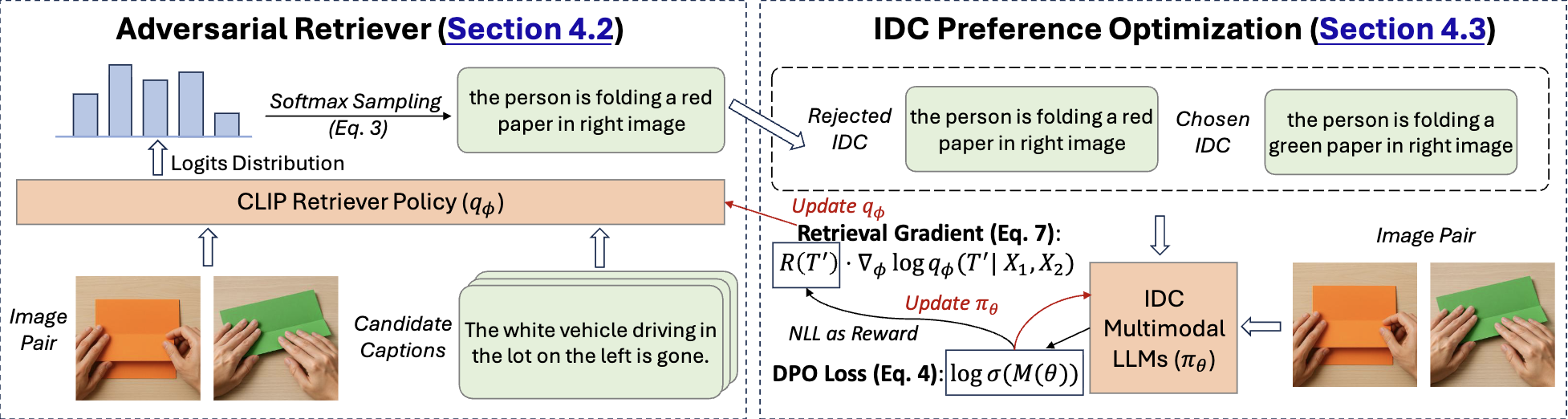
We formulate image difference captioning as a preference-optimization problem and introduce an adversarial hard-negative retriever plus DPO-style training to better capture fine-grained visual differences. This combines multimodal reasoning with preference-based training.
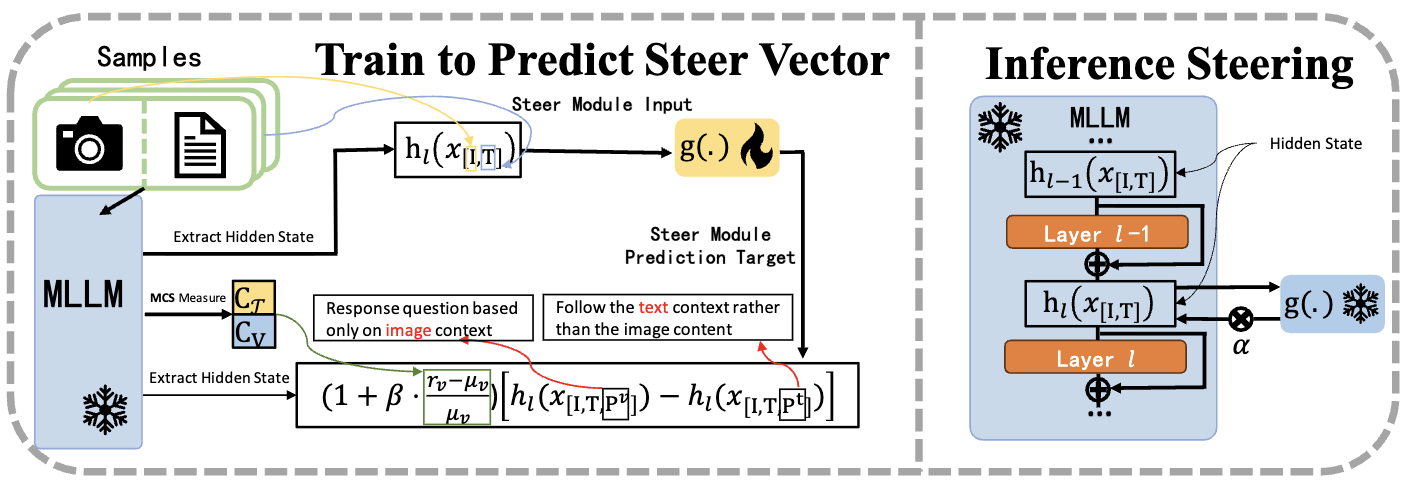
We study modality preference in MLLMs (e.g., over-reliance on text vs. images) and propose an entropy-based diagnostic plus a sample-wise steering mechanism that adjusts steering intensity per input to avoid generation collapse while still shifting modality usage in a controlled way.
Experience
Dell Technologies
Jul 2022 - Sept 2025
AI Research Intern | Hopkinton, MA
Built production-grade multi-agent LLM systems with 40% latency reduction, scalable RAG pipelines, and autonomous monitoring infrastructure.
Software Engineer II | Santa Clara, CA
Architected TOSCA-based orchestration framework and real-time infrastructure digital twin with graph databases, achieving 30% faster provisioning and 25% response time improvement.
Software Engineer I | Santa Clara, CA
Automated GPU-accelerated ML infrastructure with Kubernetes operators (20% faster deployment), redesigned gRPC services leading a 4-person team, and expanded observability coverage by 30%.
Machine Learning Researcher
Spartan Superway | San Jose, CA
Developed real-time vehicle detection and tracking system using YOLOv5 and BiLSTM for autonomous transportation, achieving 0.45 RMSE.
Open Source Developer
The Apache Software Foundation | Remote
Contributed to Apache Tika, enhancing file detection and content analysis capabilities.
Software Developer Intern
Confluxsys LLC | Menlo Park, CA
Built data mining modules using Spark, Scala, and GNNs, improving pipeline throughput by 25% and reducing job runtimes by 45% for healthcare and finance clients.
Teaching
- CSE 258: Web Mining and Recommender Systems (Sep 2025 - Present)
- CSE 153: Machine Learning for Music (Mar 2025 - Sep 2025)
- CS Peer Tutor: SJSU Peer Connections (Jan 2022 - May 2022)
- CS46B: Introduction to Data Structures (Aug 2021 - May 2022)
- CS149: Operating Systems (Aug 2021 - Jan 2022)
- Math Workshop Facilitator: Calculus II (Jan 2020 - Aug 2021)
Education
Bachelor of Science in Software Engineering
GPA: 3.87/4.00 (Summa Cum Laude)
Projects
Designed multi-agent framework for PII-safe data generation and fine-tuned 2 open-source LLMs achieving 99% PII removal with 270-question evaluation benchmark.
Built real-time vehicle detection and tracking system with YOLOv5 and BiLSTM achieving 0.45 RMSE, optimized for Raspberry Pi deployment.